Путь к тому, чтобы стать опытным и успешным программистом, труден, но он, безусловно, достижим. Структуры данных являются основным компонентом, которым должен овладеть каждый студент-программист, и есть вероятность, что вы уже изучили или работали с некоторыми базовыми структурами данных, такими как массивы или списки.
Интервьюеры, как правило, предпочитают задавать вопросы, связанные со структурами данных, поэтому, если вы готовитесь к собеседованию, вам нужно будет освежить свои знания о структурах данных. Читайте дальше, пока мы перечисляем самые важные структуры данных для программистов и собеседований.
Связанные списки являются одной из самых основных структур данных и часто являются отправной точкой для студентов в большинстве курсов по структурам данных. Связанные списки - это линейные структуры данных, обеспечивающие последовательный доступ к данным.
Элементы в связанном списке хранятся в отдельных узлах, которые связаны (связаны) с помощью указателей. Вы можете представить связанный список как цепочку узлов, связанных друг с другом с помощью разных указателей.
Связанный: Введение в использование связанных списков в Java
Прежде чем мы углубимся в специфику различных типов связанных списков, важно понять структуру и реализацию отдельного узла. Каждый узел в связанном списке имеет по крайней мере один указатель (узлы двусвязного списка имеют два указателя), который соединяет его со следующим узлом в списке и самим элементом данных.
Каждый связанный список имеет головной и конечный узел. Узлы односвязного списка имеют только один указатель, который указывает на следующий узел в цепочке. Помимо следующего указателя, узлы двусвязного списка имеют еще один указатель, указывающий на предыдущий узел в цепочке.
Вопросы на собеседовании, связанные со связанными списками, обычно касаются вставки, поиска или удаления определенного элемента. Вставка в связанный список занимает O (1) раз, но удаление и поиск могут занять O (n) в худшем случае. Так что связанные списки не идеальны.
2. Двоичное дерево
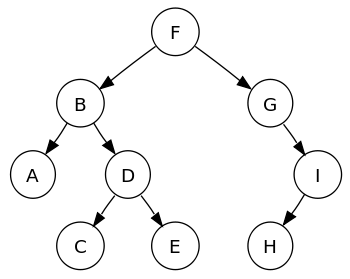
Двоичные деревья являются наиболее популярным подмножеством структуры данных древовидного семейства; элементы в двоичном дереве расположены в иерархии. Другие типы деревьев включают AVL, красно-черные, B-деревья и т. Д. Узлы двоичного дерева содержат элемент данных и два указателя на каждый дочерний узел.
Каждый родительский узел в двоичном дереве может иметь максимум два дочерних узла, и каждый дочерний узел, в свою очередь, может быть родительским для двух узлов.
Связанный: Руководство по бинарным деревьям для новичков
Бинарное дерево поиска (BST) хранит данные в отсортированном порядке, где элементы с ключом-значением меньше родительского узел хранится слева, а элементы со значением ключа больше, чем у родительского узла, хранятся на правильно.
Бинарные деревья обычно задают на собеседованиях, поэтому, если вы готовитесь к собеседованию, вы должны знать, как сгладить двоичное дерево, найти определенный элемент и многое другое.
3. Хеш-таблица
Хеш-таблицы или хеш-карты - это высокоэффективная структура данных, которая хранит данные в формате массива. Каждому элементу данных присваивается уникальное значение индекса в хеш-таблице, что позволяет осуществлять эффективный поиск и удаление.
Процесс назначения или сопоставления ключей в хэш-карте называется хешированием. Чем эффективнее хеш-функция, тем выше эффективность самой хеш-таблицы.
Каждая хэш-таблица хранит элементы данных в паре значение-индекс.
Где значение - это данные, которые нужно сохранить, а индекс - это уникальное целое число, используемое для отображения элемента в таблицу. Хеш-функции могут быть очень сложными или очень простыми, в зависимости от требуемой эффективности хеш-таблицы и того, как вы будете разрешать коллизии.
Коллизии часто возникают, когда хеш-функция производит одно и то же отображение для разных элементов; Коллизии хэш-карты можно разрешить по-разному, используя открытую адресацию или цепочку.
Хеш-таблицы или хеш-карты имеют множество различных приложений, включая криптографию. Это структура данных первого выбора, когда требуется вставка или поиск за постоянное время O (1).
4. Стеки
Стеки - одна из самых простых структур данных, с которыми довольно легко справиться. Структура данных стека - это, по сути, любой реально существующий стек (представьте себе стопку коробок или пластин), работающий по принципу LIFO (Last In First Out).
Свойство LIFO Stacks означает, что элемент, который вы вставили последним, будет доступен первым. Вы не можете получить доступ к элементам ниже верхнего элемента в стеке, не выталкивая элементы над ним.
У стека есть две основные операции: push и pop. Push используется для вставки элемента в стек, а pop удаляет самый верхний элемент из стека.
У них также есть множество полезных приложений, поэтому интервьюеры часто задают вопросы, связанные со стеками. Очень важно знать, как переворачивать стек и оценивать выражения.
5. Очереди
Очереди похожи на стеки, но работают по принципу FIFO (First In First Out), что означает, что вы можете получить доступ к элементам, которые вы вставили ранее. Структуру данных очереди можно визуализировать как любую реальную очередь, в которой люди располагаются в соответствии с порядком их прибытия.
Операция вставки в очередь называется постановкой в очередь, а удаление / удаление элемента из начала очереди называется выводом из очереди.
Связанный: Руководство для начинающих по пониманию очередей и очередей с приоритетом
Очереди с приоритетом являются неотъемлемым приложением очередей во многих жизненно важных приложениях, таких как планирование ЦП. В очереди с приоритетом элементы упорядочиваются в соответствии с их приоритетом, а не порядком поступления.
6. Кучи

Кучи - это тип двоичного дерева, в котором узлы расположены в порядке возрастания или убывания. В минимальной куче значение ключа родительского элемента равно или меньше, чем у его дочерних элементов, а корневой узел содержит минимальное значение всей кучи.
Точно так же корневой узел максимальной кучи содержит максимальное значение ключа кучи; вы должны сохранить свойство min / max heap во всей куче.
Связанный: Куча vs. Стеки: что их отличает?
Кучи имеют множество приложений из-за их очень эффективной природы; в первую очередь очереди с приоритетами часто реализуются через кучи. Они также являются основным компонентом алгоритмов heapsort.
Изучите структуры данных
Поначалу структуры данных могут показаться утомительными, но на них нужно потратить достаточно времени, и вы обнаружите, что они легкие, как пирог.
Они являются жизненно важной частью программирования, и почти каждый проект потребует их использования. Очень важно знать, какая структура данных идеальна для данного сценария.
Эти алгоритмы необходимы для рабочего процесса каждого программиста.
Читать далее
- Программирование
- Анализ данных
- Советы по кодированию

Фахад - писатель в MakeUseOf, в настоящее время специализируется на компьютерных науках. Как заядлый технический писатель, он следит за тем, чтобы оставаться в курсе последних технологий. Он особенно интересуется футболом и технологиями.
Подписывайтесь на нашу новостную рассылку
Подпишитесь на нашу рассылку технических советов, обзоров, бесплатных электронных книг и эксклюзивных предложений!
Нажмите здесь, чтобы подписаться


